ML Problem Framing
Example of framing machine learning problems
Scenario
Imagine you work at a bank, and the current fraud detection workflow isn’t performing well. Your boss asks you to explore machine learning approaches to improve the detection and flagging of fraudulent credit card transactions. While researching online, you find Credit Card Fraud Detection dataset on Kaggle that could be useful for creating a prototype.
Problem Framing
Is the provided dataset appropriate for the specified objective? What type of data would ideally solve your problem or research question? Are there better-suited datasets available on the internet for this objective?
- The ideal dataset should contain data about the transactions, e.g. transaction details, customer details, etc., which could be used to classify the fraud transaction. Moreover, it should contain an indicator whether it is a fraud transaction for supervised machine learning methods. If such indicator is not available, we can apply outlier detection to identify transactions which deviate much from normal transactions as frauds.
- The provided dataset contains target column ‘Class’ that indicates whether it is a fraud transaction. It also contains other columns (‘Time’, ‘Amount’, ‘V1-V28’) which can be used as features to predict the target column ‘Class’.
- There are some caveats for using the dataset.
- The dataset is a transformed dataset with PCA-transformed columns ‘V1’ - ‘V28’. Without having the original dataset, we are not sure how the PCA transformation is performed. We cannot guarantee if the same transformation can be applied to any new data (e.g. real-world data of new transactions)
- From the interpretation perspective, we might fail to draw any meaningful insights between the features and the target as we do not understand the meaning of the columns ‘V1’ - ‘V28’. Moreover, we might not detect any potential bias or unfairness within the ML model if the original dataset contains sensitive information, e.g. age, gender, etc.
- There could possibly be better-suited datasets, for example this dataset.
Clearly define the expected input and the ‘ideal’ output. Determine if machine learning is the appropriate method for addressing this problem.
- Data Input: Data about the transactions, for example:
- merchandise details: time, amount, merchant information, etc.
- customer details: account balance, credit score, cardholder information, etc.
- Data Output: A soft prediction (probability) whether a transaction is a fraud
- As we can clearly define the expected input and output and we can collect the data, machine learning is the appropriate method to address the problem.
If machine learning is deemed suitable, what should the model aim to achieve? How would you measure the model’s performance?
- Our objective is to detect fraudulent transactions by having a soft prediction (probability) and a threshold to determine whether a transaction is a fraud
- We can expect there would potentially be false positives (legit transactions predicted as fraud) and false negatives (fraudulent transactions predicted as legit) from the predictions and the model should balance both based on our needs. For example, more false negatives might create more bad debts, while more false positives might affect the revenue.
- Moreover, the dataset is an unbalanced dataset with less than 1% are actual fraudulent records.
- We can use evaluation metrics, e.g. precision, recall, area under precision-recall curve, etc. to measure the model performance. For example, if we are trying to minimize false negatives, we would focus more on recall (true positive rate).
How would a human tackle this issue? Can you propose any heuristic methods to solve this problem?
- It would be a data collection -> analysis by expert -> decision making -> remedy approach to solve this issue by human.
- Data collection: We collect historical legit and fraud transactions and the related information, e.g. transaction, merchant, cardholder, etc.
- Analysis by expert: Expert will deep dive into the collected data to identify any pattern/traits of the fraud transactions from the data. Moreover, they will provide a score of the likeliness of fraud for a transaction.
- Decision making: A cutoff of the score will be made to classify if a transaction is a fraud.
- Remedy: If the transaction is legit, no action is required. If it is a fraud, the money transfer will be on-hold. Further investigation will undergo.
What are the major steps required to resolve this problem?
- For machine-learning based approach, we would go through similar but slightly different steps to resolve the problem
- Data collection & wrangling: Data collection is similar to the above. We will also carry out data wrangling to handle unclean data (e.g. missing values) and transform data into desired format (e.g. scaling).
- Model training: A subset of the data will be used to train the model to learn any pattern for fraud/legit transactions. The model will then output the predictions.
- Validation/Testing: Another subset(s) of the data will be used to test the model performance, which is helpful in model selection, estimation of performance under real-world scenario, etc.
- Deployment: The defined data processing pipeline and trained model will be deployed to the existing system/workflow, which can intake the transaction data and output the prediction results to the relevant stakeholder(s) for further actions.
Draw a diagram that illustrates the input, output, and key stages of the problem-solving process.
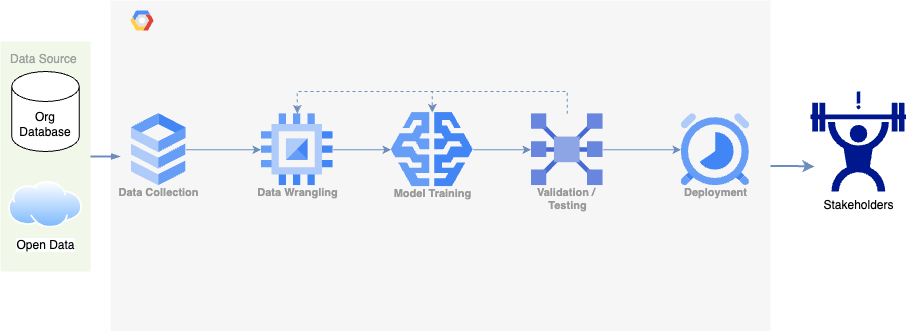
Which type of machine learning would be best suited for your problem? What specific machine learning technique would be most effective for this problem?
- We have labelled data of legit/fraud transactions and our goal is to classify the transactions. Supervised machine learning is best-suited.
- Linear regression can be applied first to observe any linear relationship between the target and the features, and we can obtain a baseline performance.
- Given the possible non-linear relationship between the target and the features, non-linear algorithms (e.g. SVM) can be applied and we can observe if there is any significant improvement in model performance.
- Given the variety of data types (textual, numerical, etc.), decision tree based algorithm (gradient boosted tree) can be applied and we can observe if there is any significant improvement in model performance.