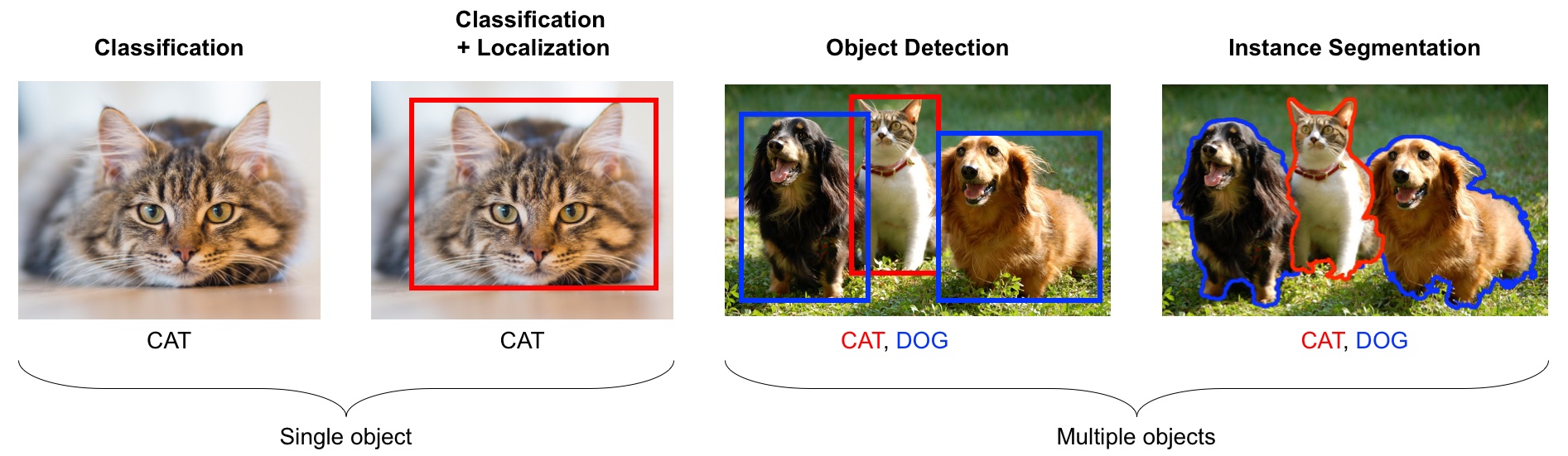
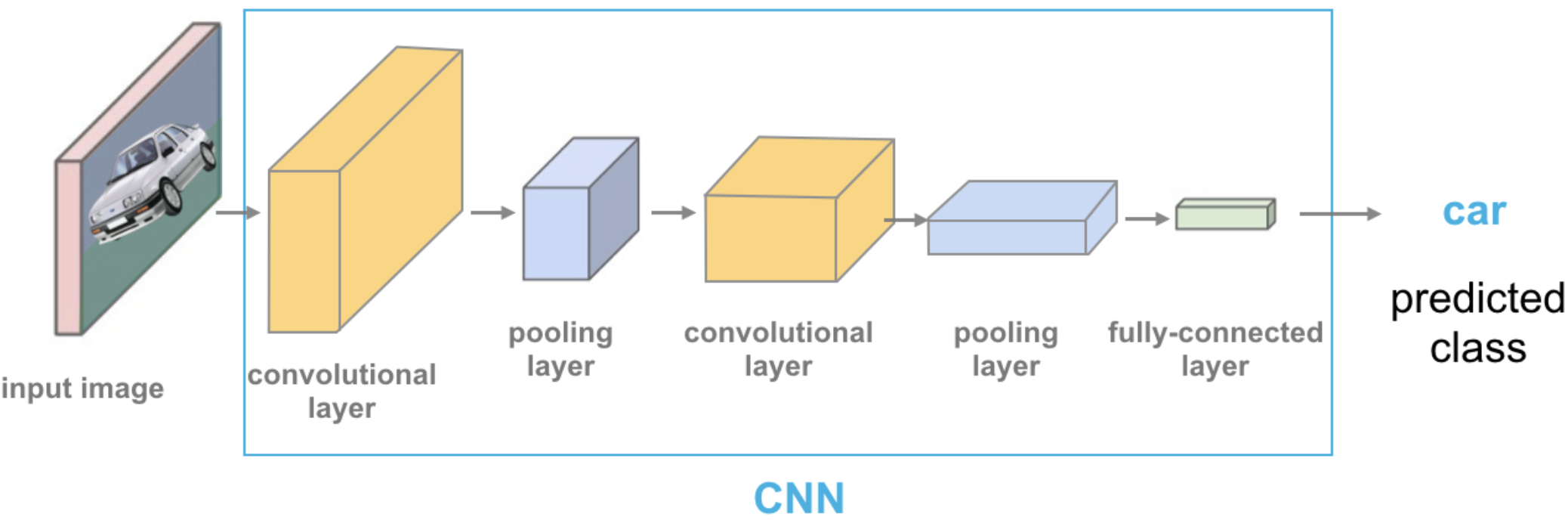
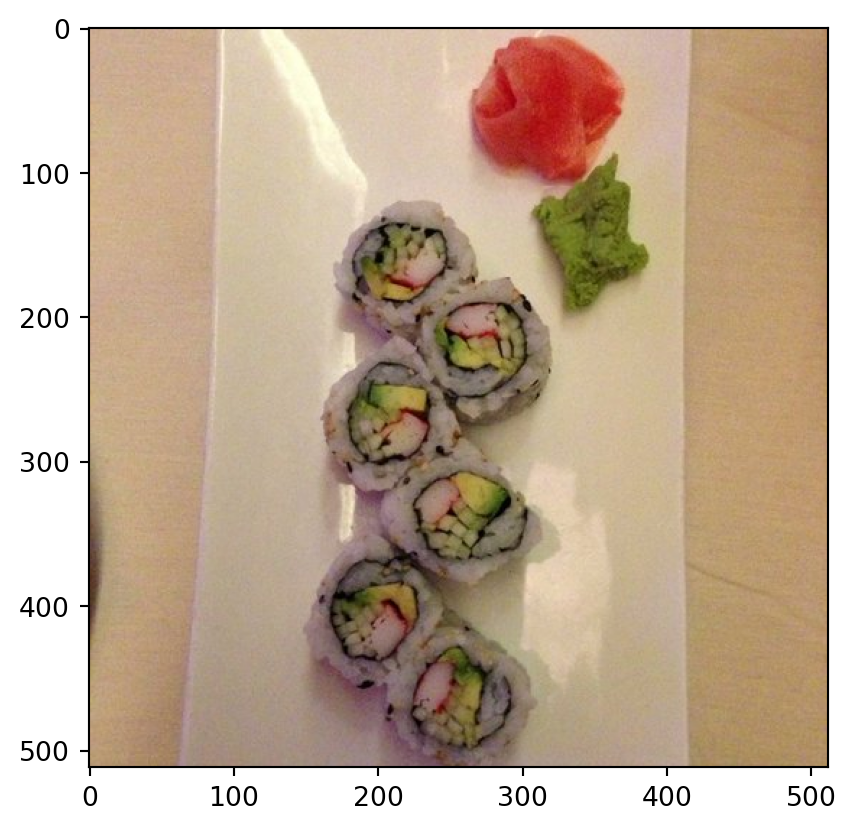
Class Probability score
cucumber, cuke 0.146
plate 0.117
guacamole 0.099
Granny Smith 0.091
--------------------------------------------------------------
Class Probability score
fig 0.637
pomegranate 0.193
grocery store, grocery, food market, market 0.041
crate 0.023
--------------------------------------------------------------
Class Probability score
toilet seat 0.171
safety pin 0.060
bannister, banister, balustrade, balusters, handrail 0.039
bubble 0.035
--------------------------------------------------------------
Class Probability score
vase 0.078
thimble 0.074
plate rack 0.049
saltshaker, salt shaker 0.047
--------------------------------------------------------------
Class Probability score
pizza, pizza pie 0.998
frying pan, frypan, skillet 0.001
potpie 0.000
French loaf 0.000
--------------------------------------------------------------
Class Probability score
patio, terrace 0.213
fountain 0.164
lakeside, lakeshore 0.097
sundial 0.088
--------------------------------------------------------------