
| Age | Total_Bilirubin | Direct_Bilirubin | Alkaline_Phosphotase | Alamine_Aminotransferase | Aspartate_Aminotransferase | Total_Protiens | Albumin | Albumin_and_Globulin_Ratio | Target |
|---|---|---|---|---|---|---|---|---|---|
| 40 | 14.5 | 6.4 | 358 | 50 | 75 | 5.7 | 2.1 | 0.50 | Disease |
| 33 | 0.7 | 0.2 | 256 | 21 | 30 | 8.5 | 3.9 | 0.80 | Disease |
| 24 | 0.7 | 0.2 | 188 | 11 | 10 | 5.5 | 2.3 | 0.71 | No Disease |
| 60 | 0.7 | 0.2 | 171 | 31 | 26 | 7.0 | 3.5 | 1.00 | No Disease |
| 18 | 0.8 | 0.2 | 199 | 34 | 31 | 6.5 | 3.5 | 1.16 | No Disease |
Introduction to Machine Learning
Which cat do you think is AI-generated?
- A
- B
- Both
- None
- What clues did you use to decide?
What is AI, ML, DL?
- Artificial Intelligence (AI): Making computers act smart
- Machine Learning (ML): Learning patterns from data
- Deep Learning (DL): Using neural networks to learn complex patterns

Image classification
- Imagine we want a system that can tell cats and foxes apart.
- How might we do this with traditional programming? With ML?

| Image ID | Whiskers Present | Ear Size | Face Shape | Fur Color | Eye Shape | Label |
|---|---|---|---|---|---|---|
| 1 | Yes | Small | Round | Mixed | Round | Cat |
| 2 | Yes | Medium | Round | Brown | Almond | Cat |
| 3 | Yes | Large | Pointed | Red | Narrow | Fox |
| 4 | Yes | Large | Pointed | Red | Narrow | Fox |
| 5 | Yes | Small | Round | Mixed | Round | Cat |
| 6 | Yes | Large | Pointed | Red | Narrow | Fox |
| 7 | Yes | Small | Round | Grey | Round | Cat |
| 8 | Yes | Small | Round | Black | Round | Cat |
| 9 | Yes | Large | Pointed | Red | Narrow | Fox |
Traditional programming: example
- You hard-code rules. If all of the following satisfy, it’s a fox.
- pointed face ✅
- red fur ✅
- narrow eyes ✅
- This works for normal cases, but what if there are exceptions
ML approach: example
- We don’t tell the model the exact rule. Instead, we give it many labeled images, and it learns probabilistic patterns across multiple features, not rigid rules.
- If fur is red → 90% chance of Fox.
DL approach: example
- A neural network automatically learns which features to look at (edges → textures → objects).
- No need to even specify face shape or fur colour. It learns relevant features on its own.
Example: Predicting labels of a given image
- Suppose you have a bunch of animal images. You do not have any labels associated with them and you want to predict labels of these images.
- We can use machine learning to predict labels of these images using a technique called transfer learning.

Class Probability score
tiger cat 0.636
tabby, tabby cat 0.174
Pembroke, Pembroke Welsh corgi 0.081
lynx, catamount 0.011
--------------------------------------------------------------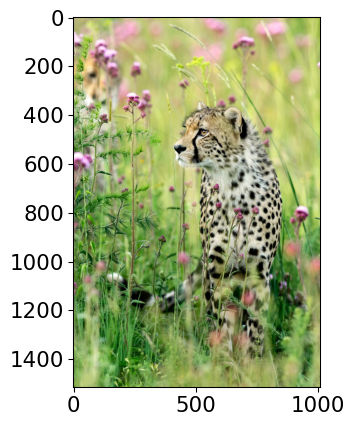
Class Probability score
cheetah, chetah, Acinonyx jubatus 0.994
leopard, Panthera pardus 0.005
jaguar, panther, Panthera onca, Felis onca 0.001
snow leopard, ounce, Panthera uncia 0.000
--------------------------------------------------------------
Class Probability score
macaque 0.885
patas, hussar monkey, Erythrocebus patas 0.062
proboscis monkey, Nasalis larvatus 0.015
titi, titi monkey 0.010
--------------------------------------------------------------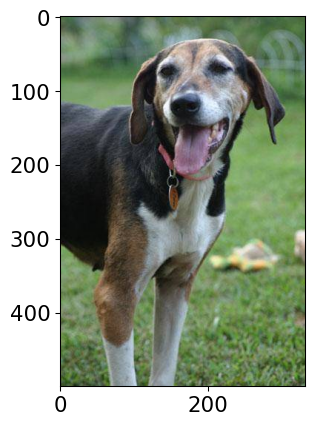
Class Probability score
Walker hound, Walker foxhound 0.582
English foxhound 0.144
beagle 0.068
EntleBucher 0.059
--------------------------------------------------------------:::
Finding groups in food images

Examining food clusters





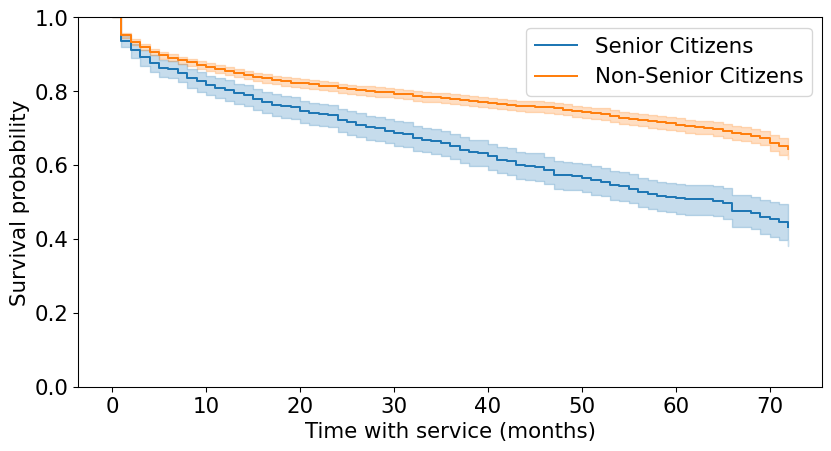
Probability of survival
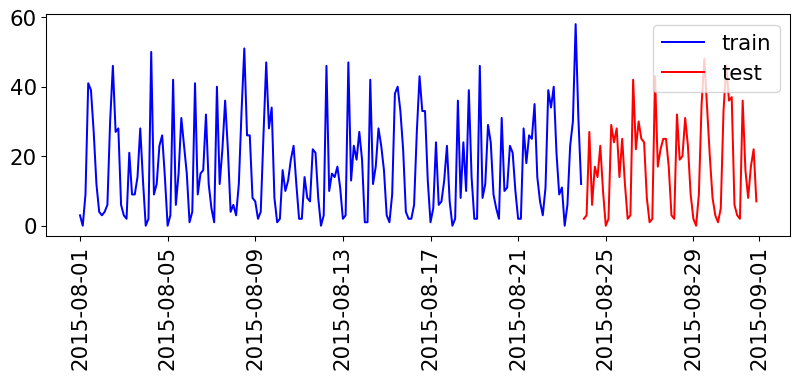
Example: Time series
starttime
2015-08-01 00:00:00 3
2015-08-01 03:00:00 0
2015-08-01 06:00:00 9
2015-08-01 09:00:00 41
2015-08-01 12:00:00 39
Freq: 3h, Name: one, dtype: int64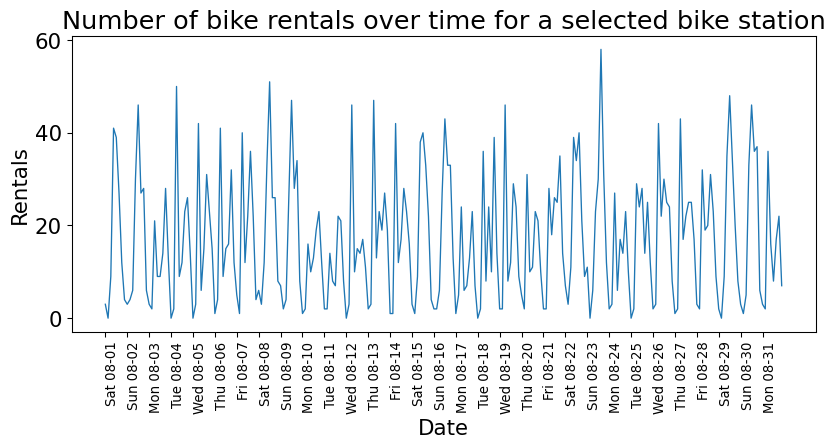
Train and test data
Predictions
Train-set R^2: 0.89
Test-set R^2: 0.84