Supervised Machine Learning Models
Tree-based models

We have seen that decision trees are prone to overfitting. There are several models that extend the basic idea of using decision trees.
Random Forest

Train an ensemble of distinct decision trees.
Gradient Boosted Trees

Each tree tries to “correct” or improve the previous tree’s prediction.
Linear models
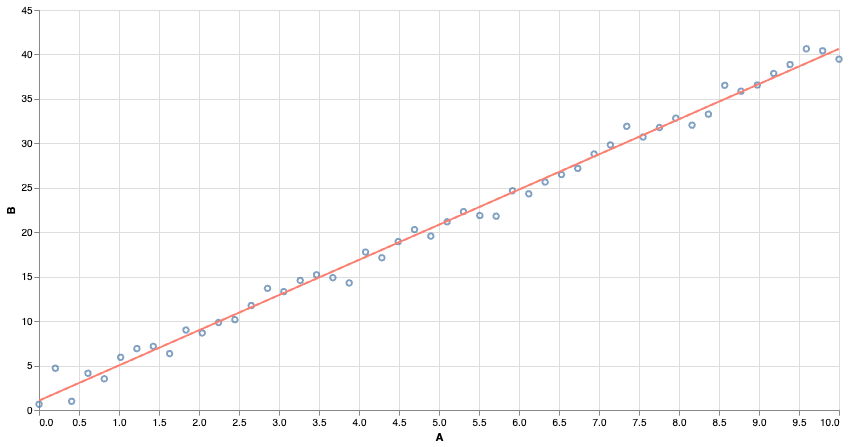
Many of you might be familiar with least-squares regression. We find the line of best fit by minimizing the ‘squared error’ of the predictions.
Linear Models
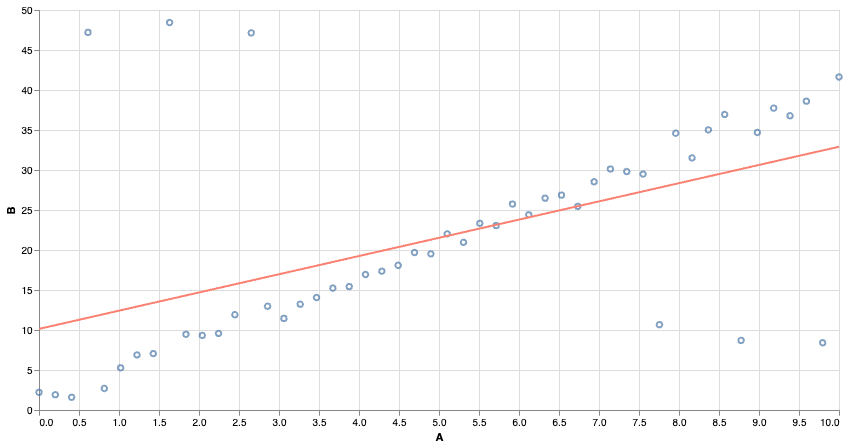
Squared Error is very sensitive to outliers. Far-away points contribute a very large squared error, and even relatively few points can affect the outcome.
Linear Models
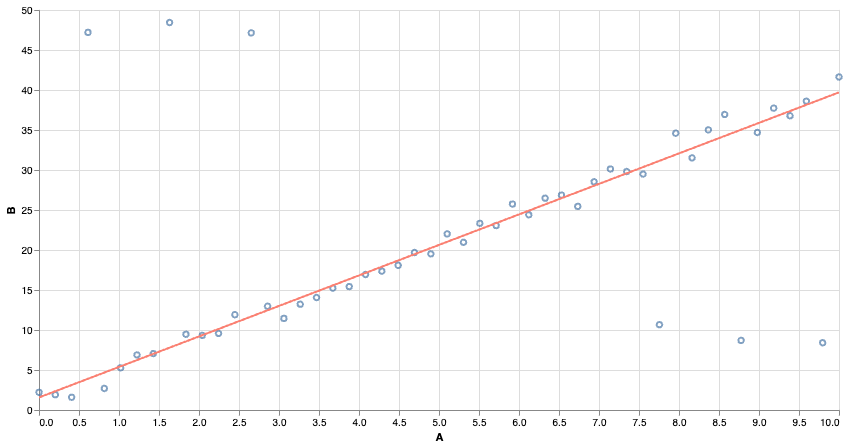
We can use other notions of “best fit”. Using absolute error makes the model more resistant to outliers!
Linear Classifiers
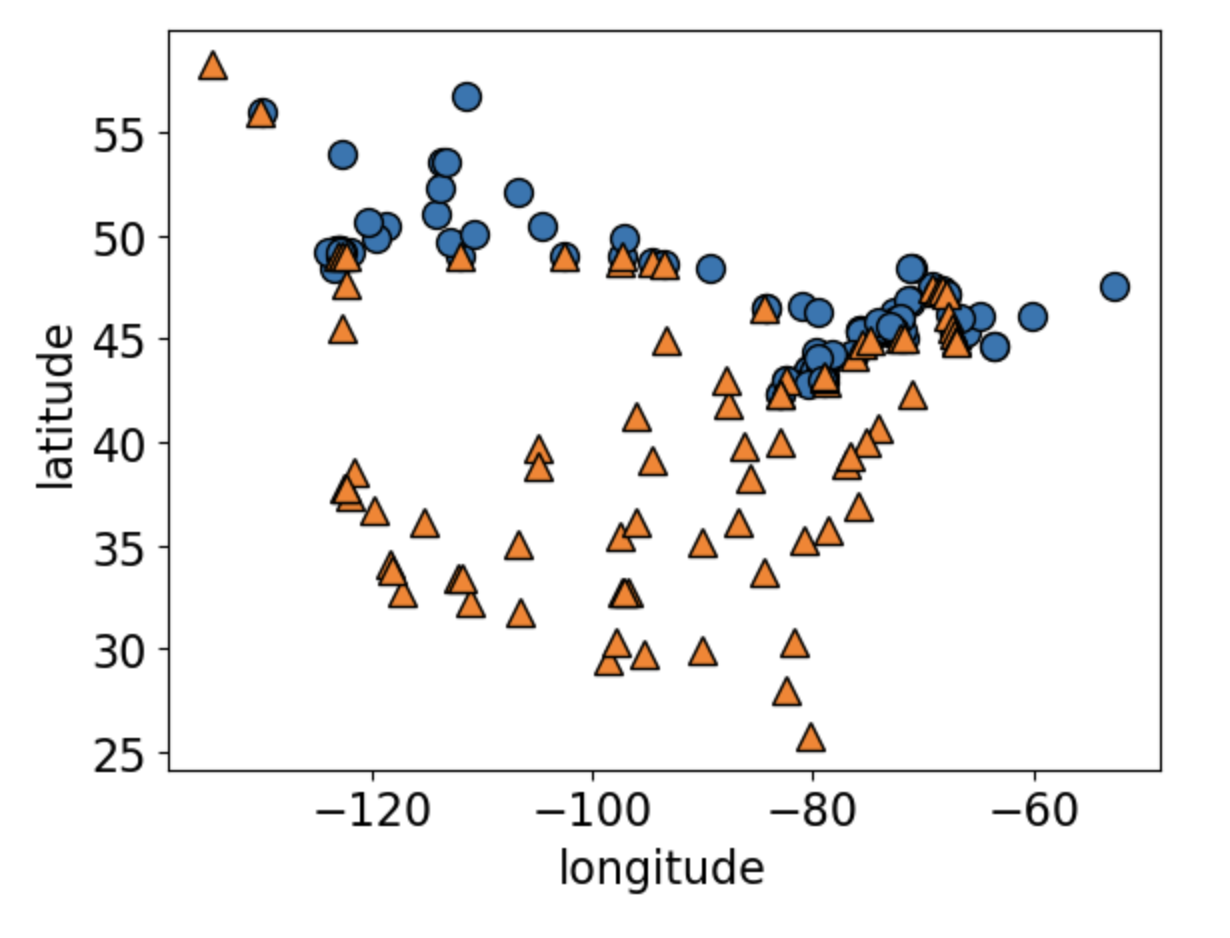
Can you guess what this dataset is?
Linear Classifiers
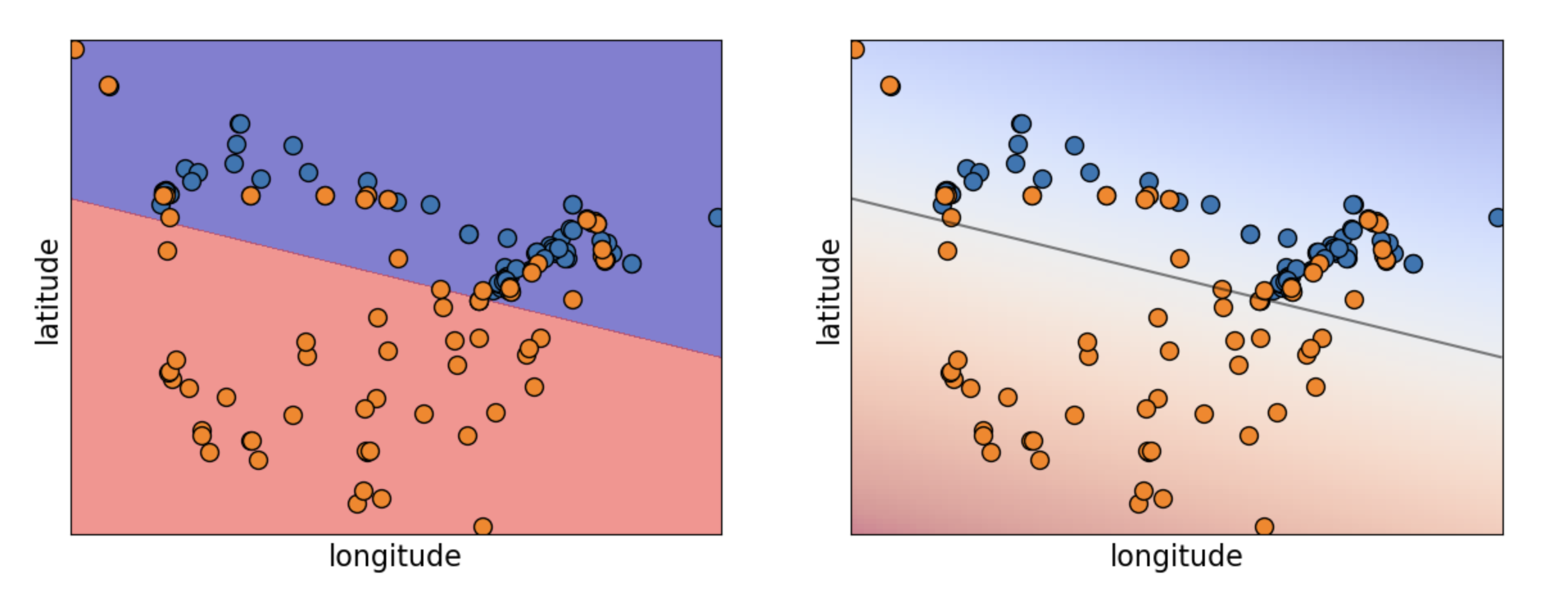
Logistic Regression predicts a linear decision boundary.
Investigating the model
They make sense! Let’s visualize the 20 most important features.
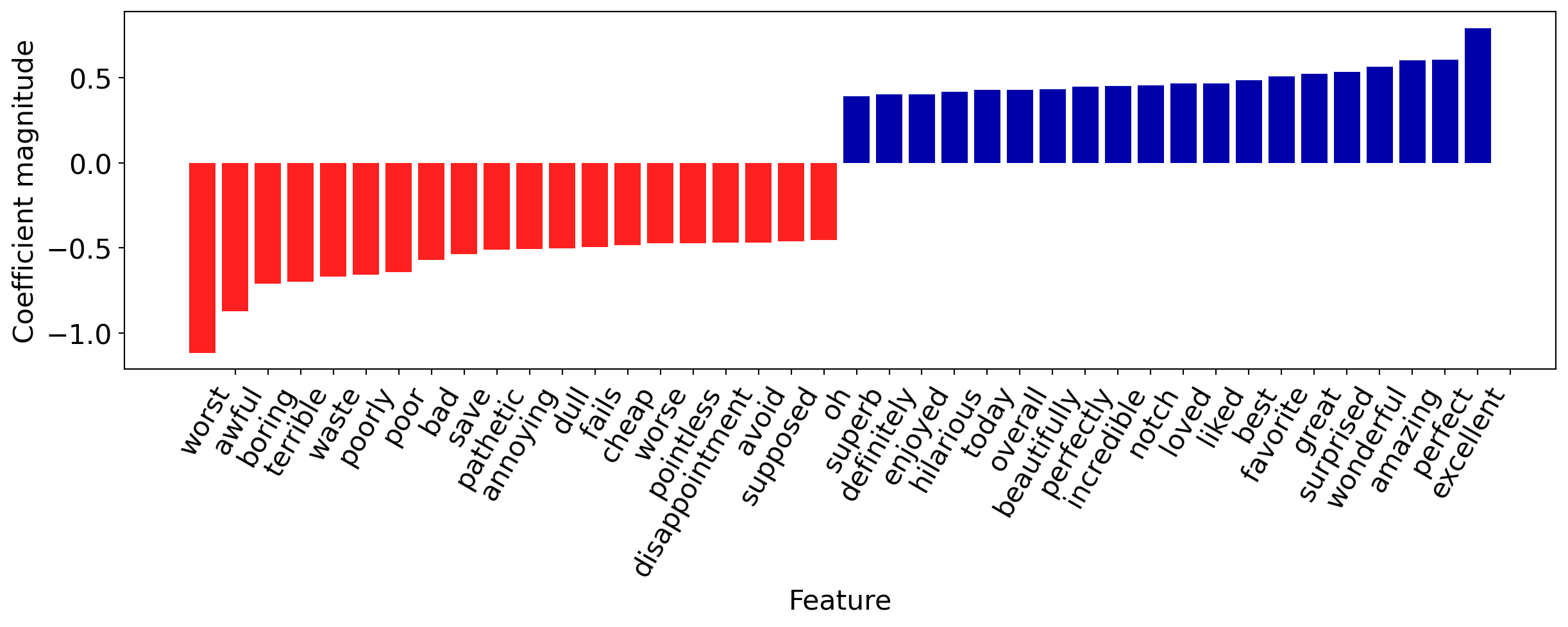
Understanding Predictions
It got a bit boring at times but the direction was excellent and the acting was flawless. Overall I enjoyed the movie and I highly recommend it!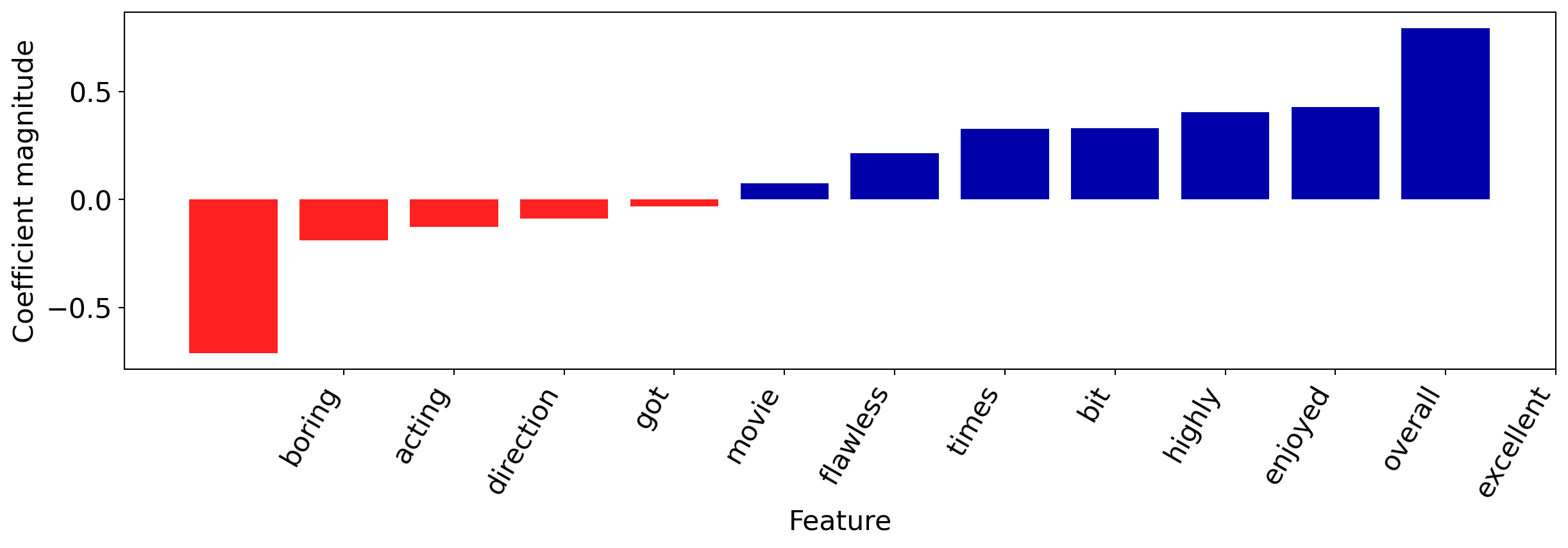
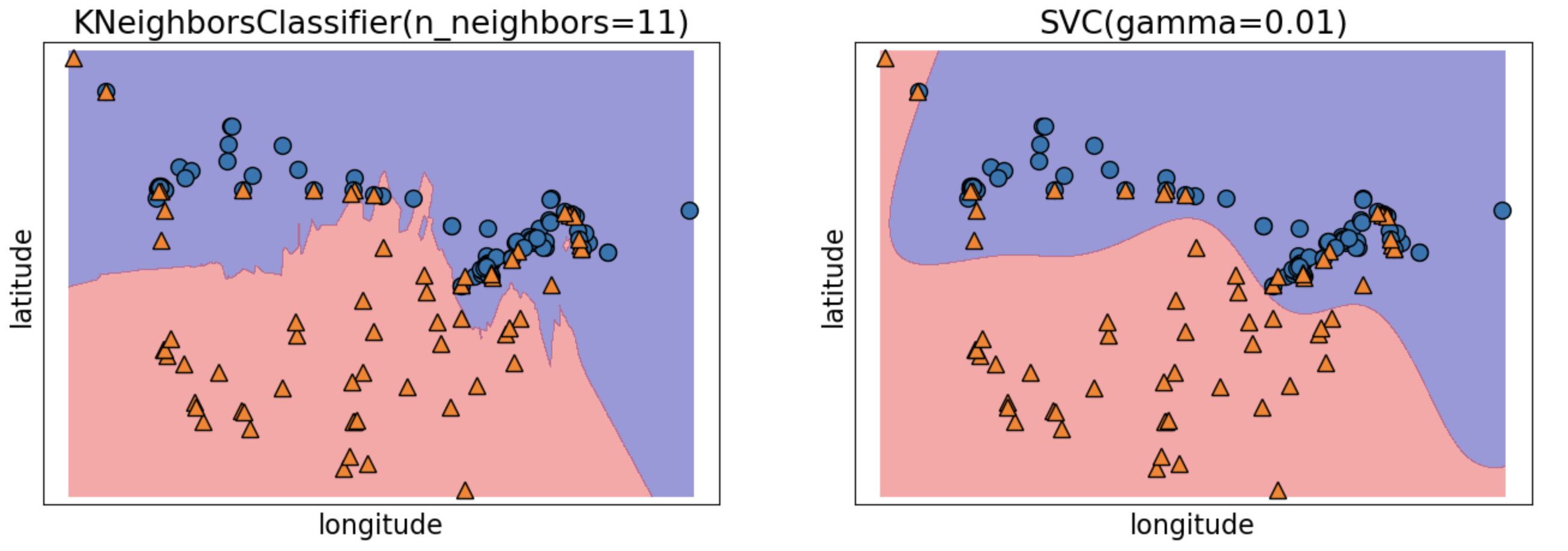
Analogy-based models
Returning to our older dataset.
Analogy-based models
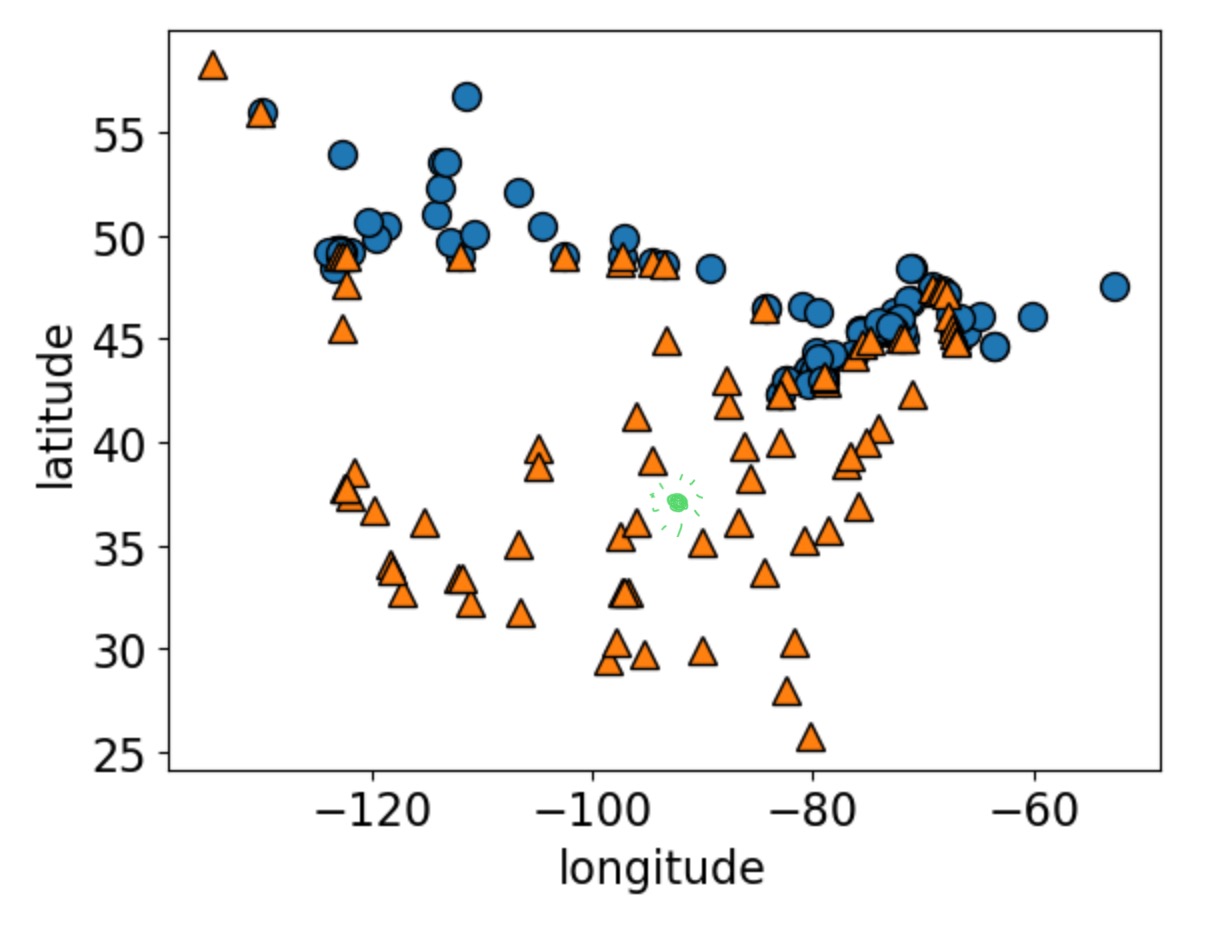
How would you classify the green dot?
KNNs and SVMs