Lecture 2: Terminology, Baselines, Decision Trees
Therapists using ChatGPT secretly 😔

Recap: Supervised learning
- We wish to find a model function \(f\) that relates \(X\) to \(y\).
- We use the model function to predict targets of new examples.

In the first part of this course, we’ll focus on supervised machine learning.
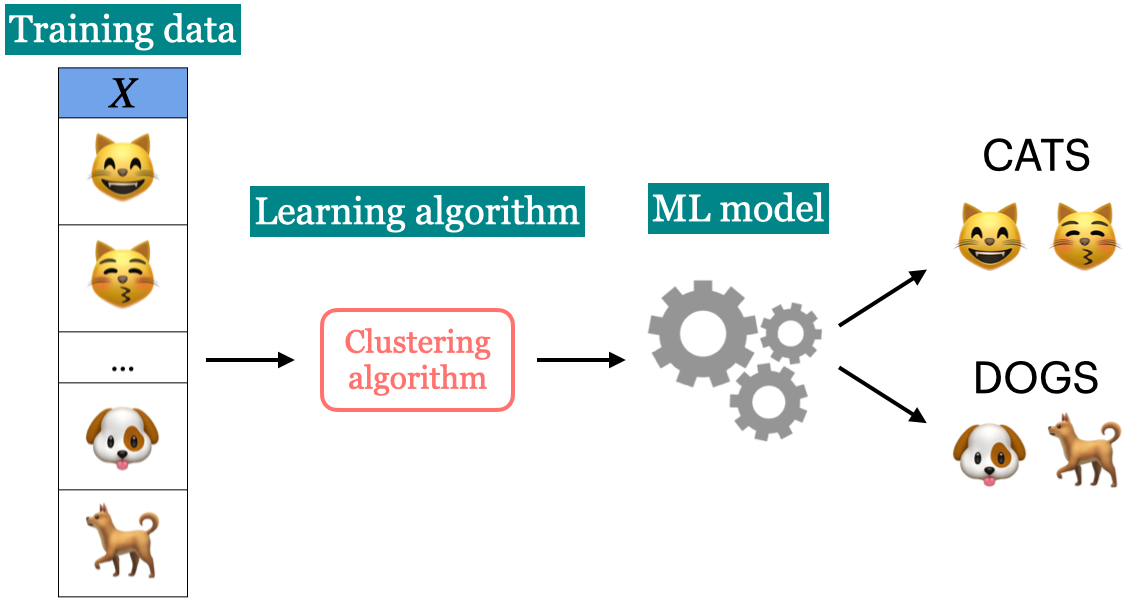
Unsupervised learning
- Training data consists of observations \(X\) without any corresponding targets.
- Unsupervised learning could be used to group similar things together in \(X\) or to find underlying structure in the data.
Decision trees intuition
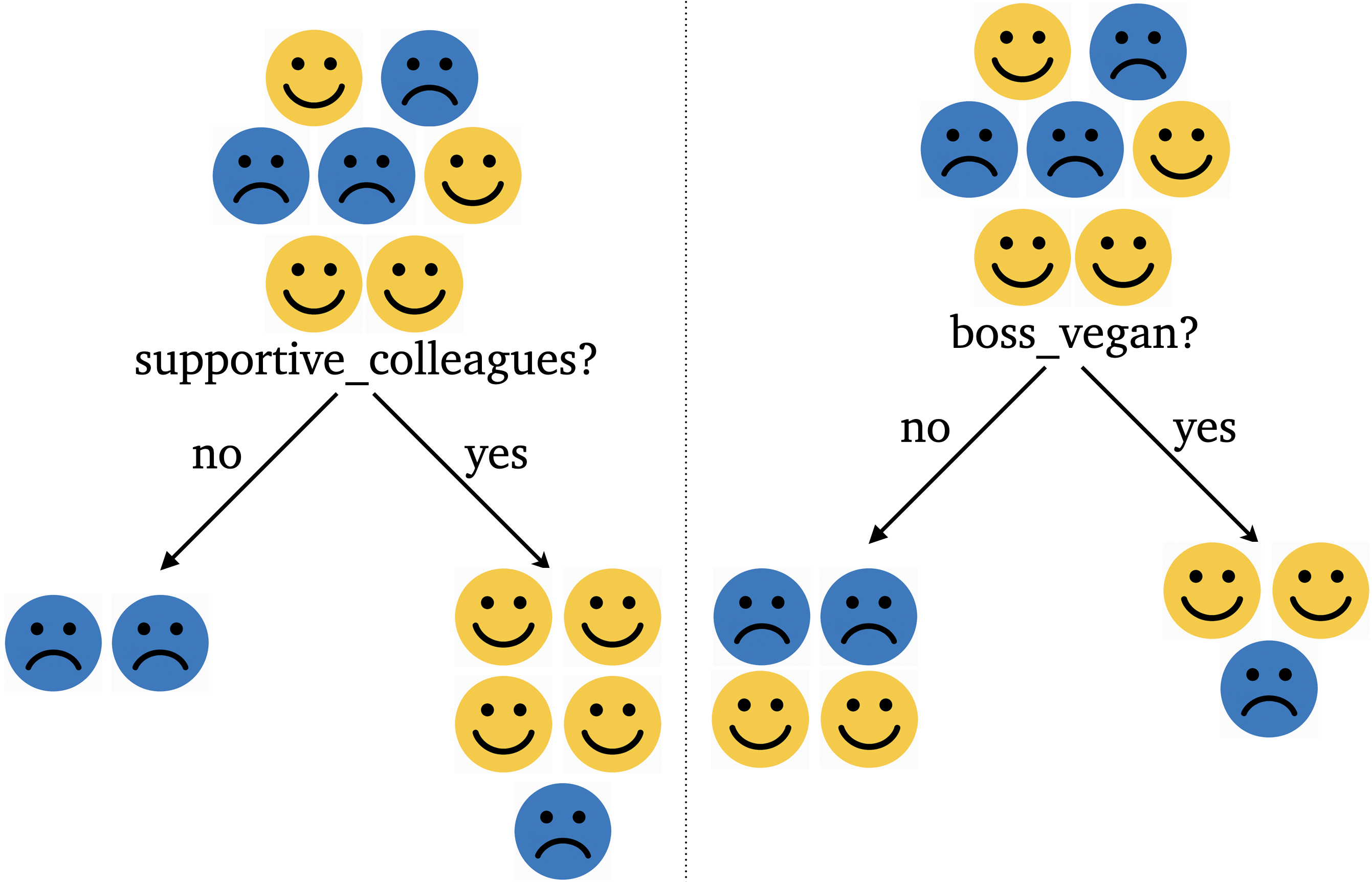
- One intuitive way to build a model is by asking a series of yes/no questions, forming a tree.
- Which question would help you best separate the happy and unhappy examples?

| supportive_colleagues | salary | free_coffee | boss_vegan | happy? | |
|---|---|---|---|---|---|
| 0 | 0 | 70000 | 0 | 1 | Unhappy |
| 1 | 1 | 60000 | 0 | 0 | Unhappy |
| 2 | 1 | 80000 | 1 | 0 | Happy |
| 3 | 1 | 110000 | 0 | 1 | Happy |
| 4 | 1 | 120000 | 1 | 0 | Happy |
| 5 | 1 | 150000 | 1 | 1 | Happy |
| 6 | 0 | 150000 | 1 | 0 | Unhappy |
Which question is more effective?
Decision tree with sklearn
Let’s train a simple decision tree on our toy dataset using sklearn
from sklearn.tree import DecisionTreeClassifier # import the classifier
from sklearn.tree import plot_tree
model = DecisionTreeClassifier(max_depth=2, random_state=1) # Create a class object
model.fit(X, y)
plot_tree(model, filled=True, feature_names = X.columns, class_names=["Happy", "Unhappy"], impurity = False, fontsize=12);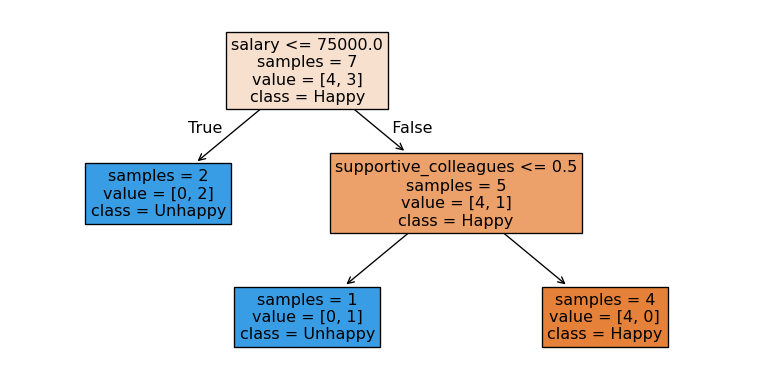
Prediction
- Given a new example, how does a decision tree predict the class of this example?
- What would be the prediction for the example below using the tree above?
- supportive_colleagues = 1, salary = 60000, coffee_machine = 0, vegan_boss = 1,
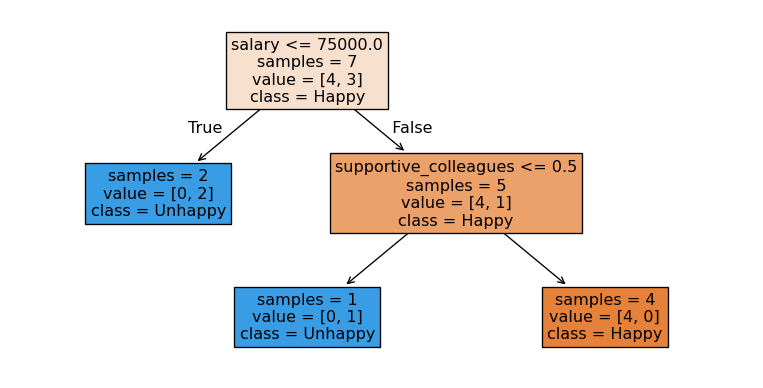
Prediction with sklearn
- What would be the prediction for the example below using the tree above?
- supportive_colleagues = 1, salary = 60000, free_coffee = 0, vegan_boss = 1,
test_example = [[1, 60000, 0, 1]]
print("Model prediction: ", model.predict(test_example))
plot_tree(model, filled=True, feature_names = X.columns, class_names = ["Happy", "Unhappy"], impurity = False, fontsize=9);Model prediction: ['Unhappy']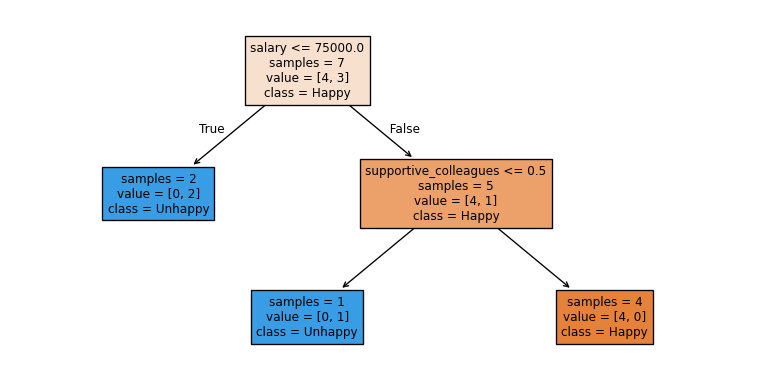
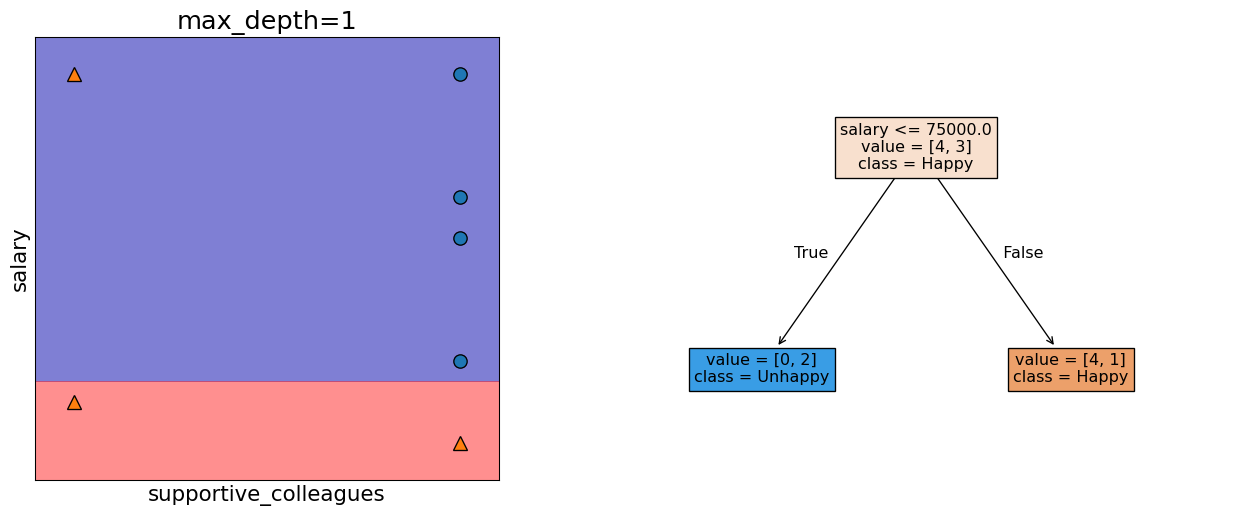
Decision boundary with max_depth=1
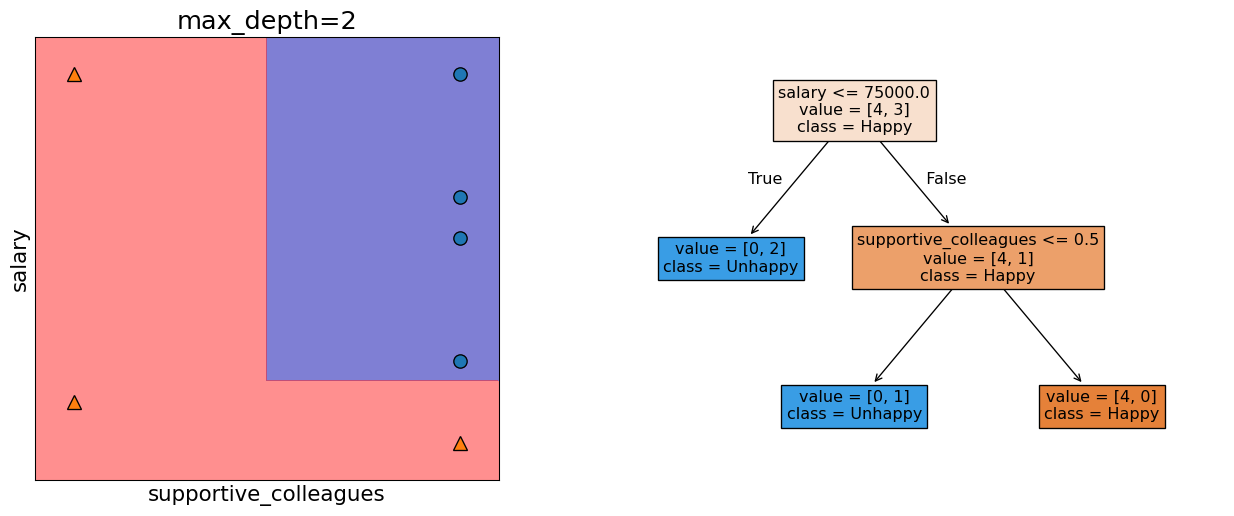
Decision boundary with max_depth=2
Summary
- Terminology
sklearnbasic steps- Decision tree intuition
![]()