CPSC 330 Lecture 13: Model Transparency, Feature Engineering and Selection
Announcements
- HW5 is due next week Monday. Make use of office hours and tutorials this week.
iClicker Exercise
- If a feature has a strong correlation with the target variable, the magnitude of its feature importance must be high.
- Feature importance tells us how the model’s predictions change when a particular feature changes.
- In linear models, a positive coefficient indicates that as the feature increases, the prediction increases.
- In tree-based models such as Random Forests or Gradient Boosted Trees, feature importances have signs that tell whether the relationship is positive or negative.
- In permutation importance, if shuffling the education feature causes a large drop in the model’s performance, it indicates that the model heavily relies on that feature for its predictions.
Model Transparency
Why bother about model transparancey?
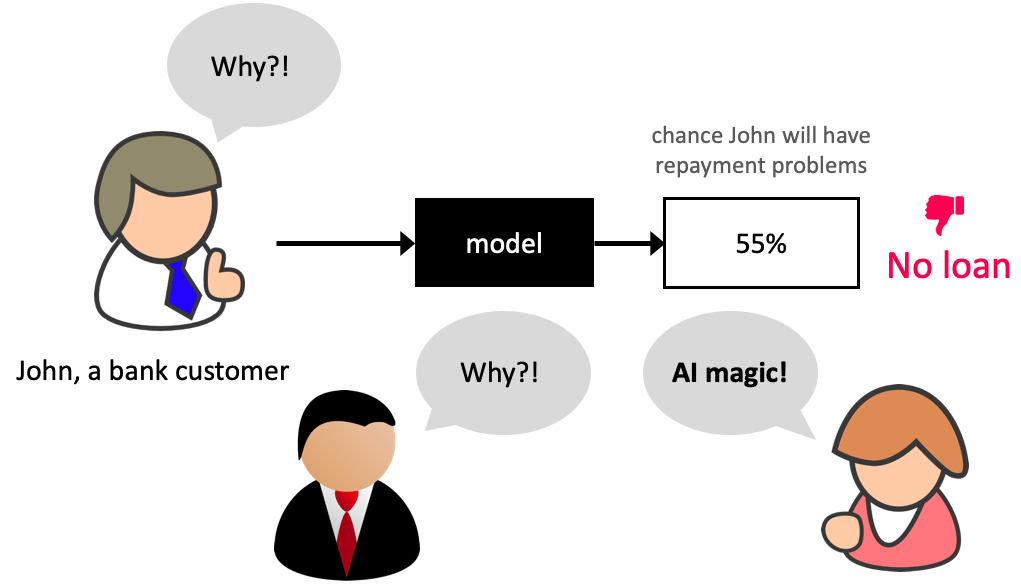
SHAP intuition
- Think of the model as a “black box” that outputs predictions.
- SHAP asks: If we treat each feature as a player contributing to the final prediction, how much credit does each one deserve?
- To answer this fairly, SHAP looks at all possible combinations of features and averages their marginal contributions.
- A marginal contribution is how much the prediction changes when you add that feature to a subset of other features.
SHAP

Class demo
iClicker Exercise SHAP
- SHAP values are model parameters learned during training.
- Coefficients in a linear model and SHAP values both quantify how much each feature contributes to a prediction, but coefficients are global while SHAP values are local.
- SHAP values can only be computed for tree-based models.
- A waterfall plot shows how each feature’s SHAP value cumulatively contributes to a single prediction.
- SHAP provides the same explanation for all examples in the dataset.
Feature engineering motivation
iClicker Exercise 13.0
Suppose you are working on a machine learning project. If you have to prioritize one of the following in your project which of the following would it be?
- The quality and size of the data
- Most recent deep neural network model
- Most recent optimization algorithm
Discussion question
- Suppose we want to predict whether a flight will arrive on time or be delayed. We have a dataset with the following information about flights:
- Departure Time
- Expected Duration of Flight (in minutes)
Upon analyzing the data, you notice a pattern: flights tend to be delayed more often during the evening rush hours. What feature could be valuable to add for this prediction task?
Garbage in, garbage out.
- Model building is interesting. But in your machine learning projects, you’ll be spending more than half of your time on data preparation, feature engineering, and transformations.
- The quality of the data is important. Your model is only as good as your data.
Activity: Measuring quality of the data
- Discuss some attributes of good- and bad-quality data
What is feature engineering?
- Better features: more flexibility, higher score, we can get by with simple and more interpretable models.
- If your features, i.e., representation is bad, whatever fancier model you build is not going to help.
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
- Jason Brownlee
Some quotes on feature engineering
A quote by Pedro Domingos A Few Useful Things to Know About Machine Learning
… At the end of the day, some machine learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used.
Some quotes on feature engineering
A quote by Andrew Ng, Machine Learning and AI via Brain simulations
Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering.
Better features usually help more than a better model
- Good features would ideally:
- capture most important aspects of the problem
- allow learning with few examples
- generalize to new scenarios.
- There is a trade-off between simple and expressive features:
- With simple features overfitting risk is low, but scores might be low.
- With complicated features scores can be high, but so is overfitting risk.
The best features may be dependent on the model you use
- Examples:
- For counting-based methods like decision trees separate relevant groups of variable values
- Discretization makes sense
- For distance-based methods like KNN, we want different class labels to be “far”.
- Standardization
- For regression-based methods like linear regression, we want targets to have a linear dependency on features.
- For counting-based methods like decision trees separate relevant groups of variable values
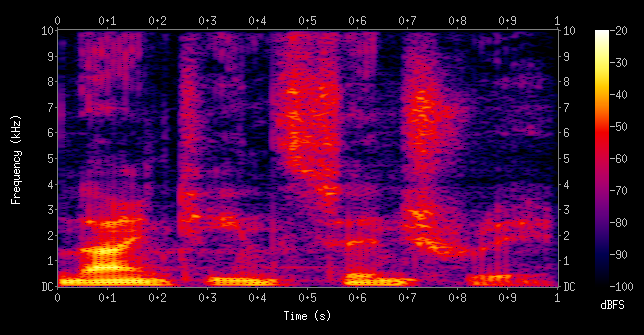
Domain-specific transformations
In some domains there are natural transformations to do:
- Spectrograms (sound data)
- Convolutions (image data)
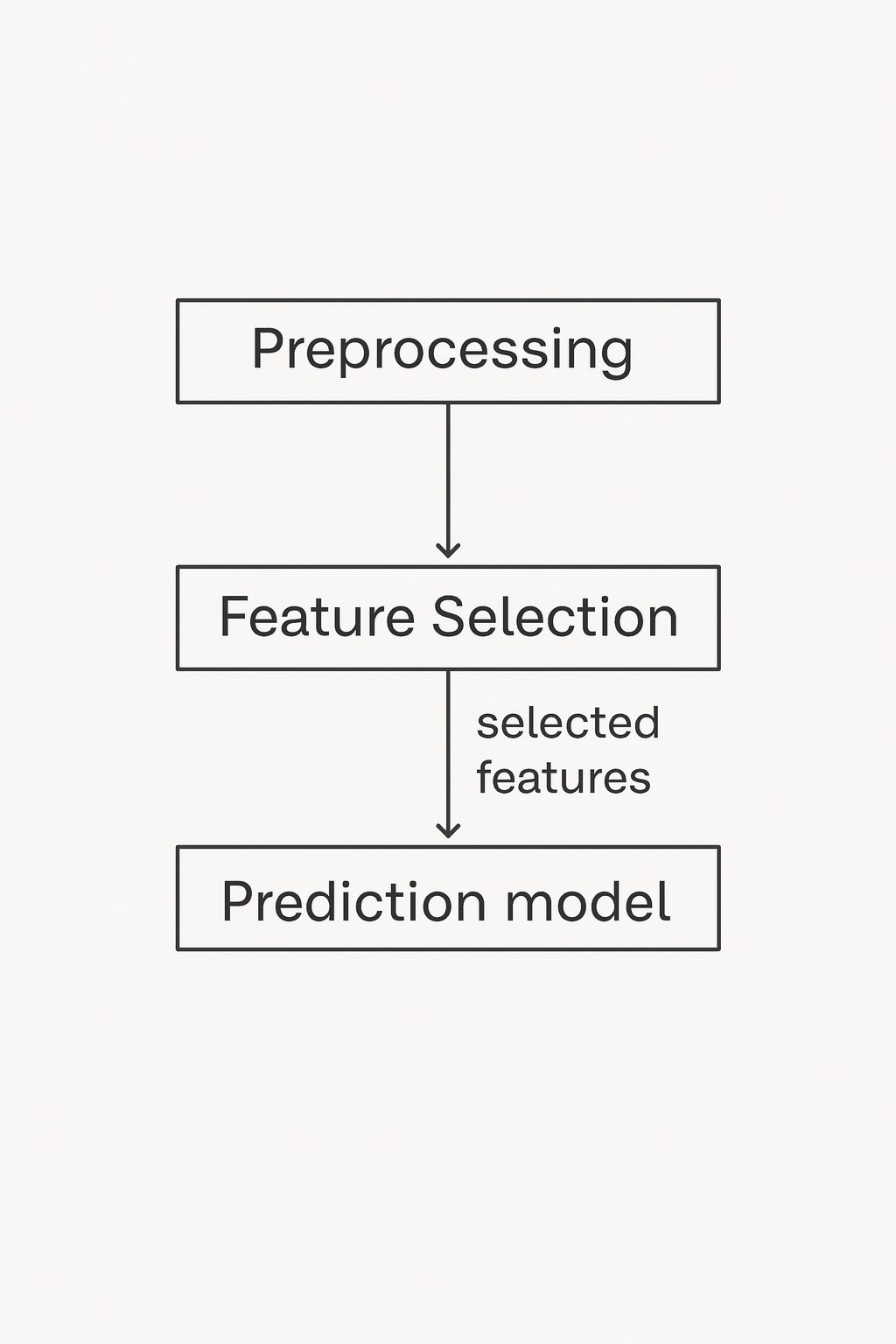
Feature selection pipeline
Two useful methods
- Model-based selection
- Use a supervised machine learning model to judge the importance of each feature.
- Keep only the most important once.
- Recursive feature elimination
- Build a series of models
- At each iteration, discard the least important feature according to the model.
(iClicker) Exercise 13.2
Select all of the following statements which are TRUE.
- You can carry out feature selection using linear models by pruning the features which have very small weights (i.e., coefficients less than a threshold).
- The order of features removed given by
rfe.ranking_is the same as the order of original feature importances given by the model.
- The order of features removed given by
![]()