CPSC 330 Lecture 15: K-Means
Announcements
- HW5 extension: New due date is tomorrow.
- HW6 will be released today. It’ll be due next week Wednesday.
(iClicker) Midterm poll
Select all of the following statements which are TRUE.
- I’m happy with my progress and learning in this course.
- I find the course content interesting, but the pace is a bit overwhelming. Balancing this course with other responsibilities is challenging
- I’m doing okay, but I feel stressed and worried about upcoming assessments.
- I’m confused about some concepts and would appreciate more clarification or review sessions.
- I’m struggling to keep up with the material. I am not happy with my learning in this course and my morale is low :(.
Supervised learning
- Training data comprises a set of observations (X) and their corresponding targets (y).
- We wish to find a model function f that relates X to y.
- Then use that model function to predict the targets of new examples.
- We have been working with this set up so far.
![]()
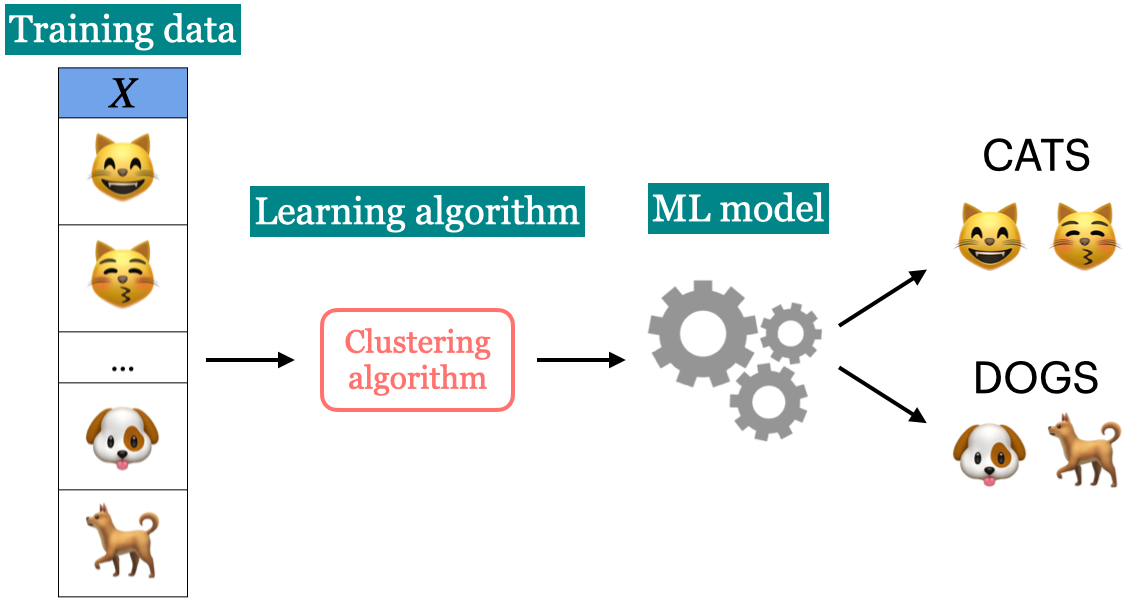
Unsupervised learning
- Training data consists of observations (X) without any corresponding targets.
- Unsupervised learning could be used to group similar things together in X or to find underlying structure in the data.
![]()
Clustering Activity
![]()
- Categorize the food items in the image and write your categories. Do you think there is one correct way to cluster these images? Why or why not?
- If you want to build a machine learning model to cluster such images how would you represent such images?
The “perfect” spaghetti sauce
Suppose you are a hypothetical spaghetti sauce company and you’re asked to create the “perfect” spaghetti sauce which makes all your customers happy. The truth is humans are diverse and there is no “perfect” spaghetti sauce. There are “perfect” spaghetti sauces that cater to different tastes!
The “perfect” spaghetti sauce
Howard Moskowitz found out that Americans fall into one of the following three categories:
- people who like their spaghetti sauce plain
- people who like their spaghetti sauce spicy
- people who like their spaghetti sauce extra chunky
![]() Reference: Malcolm Gladwell’s Ted talk
Reference: Malcolm Gladwell’s Ted talk
The “perfect” spaghetti sauce
- If one “perfect” authentic sauce satisfies 60%, of the people on average, creating several tailored sauce clusters could increase average happiness to between 75% to 78%.
- Can we apply this concept of clustering and tailoring solutions to specific groups in machine learning?
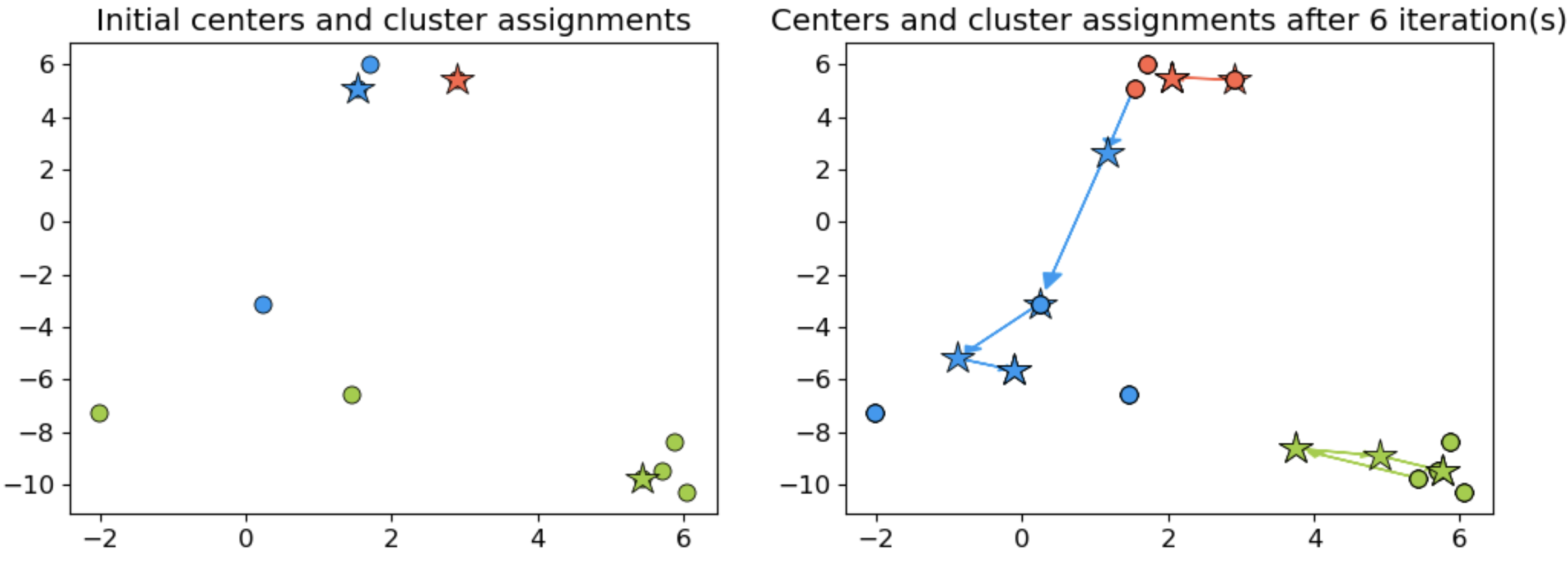
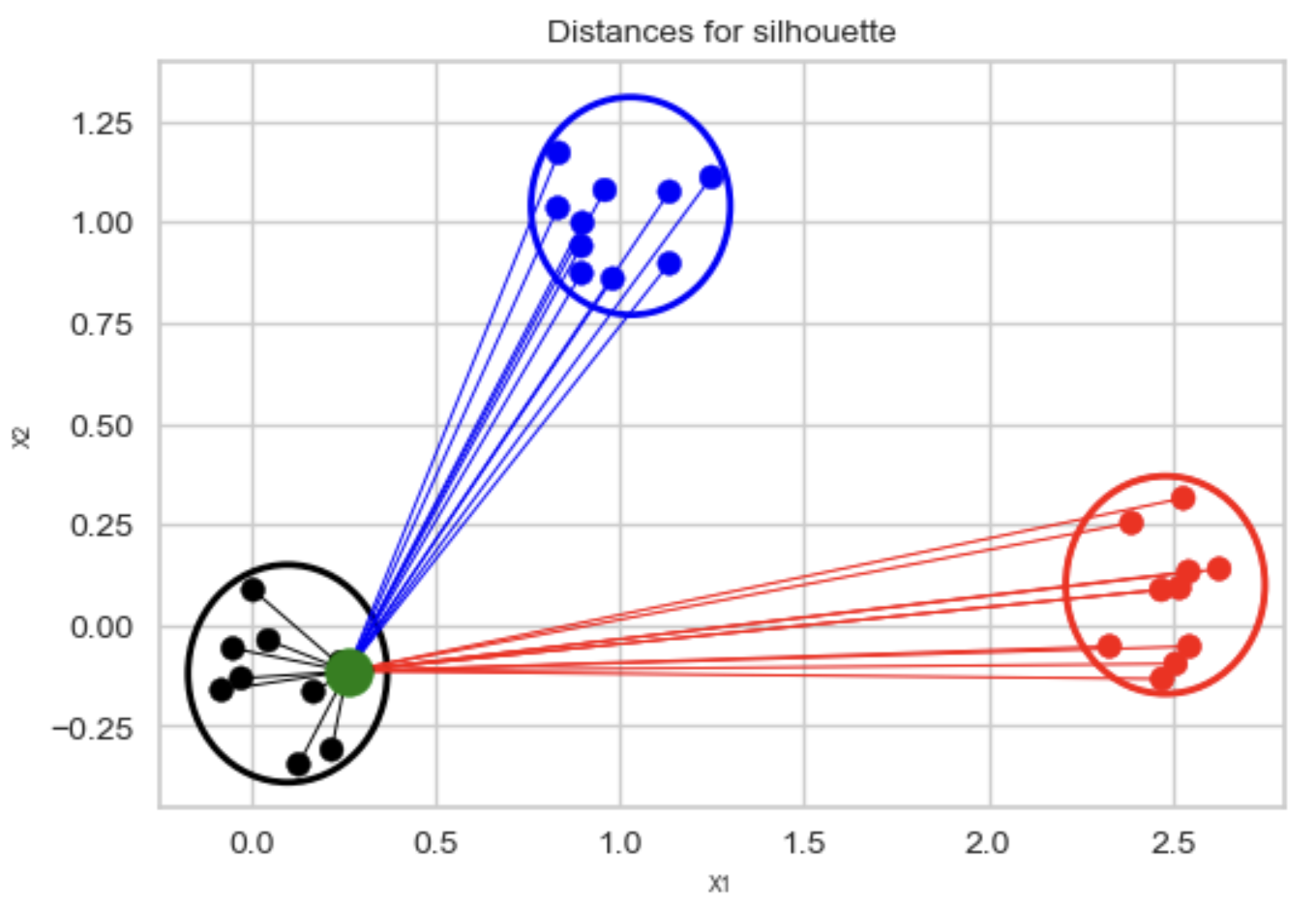
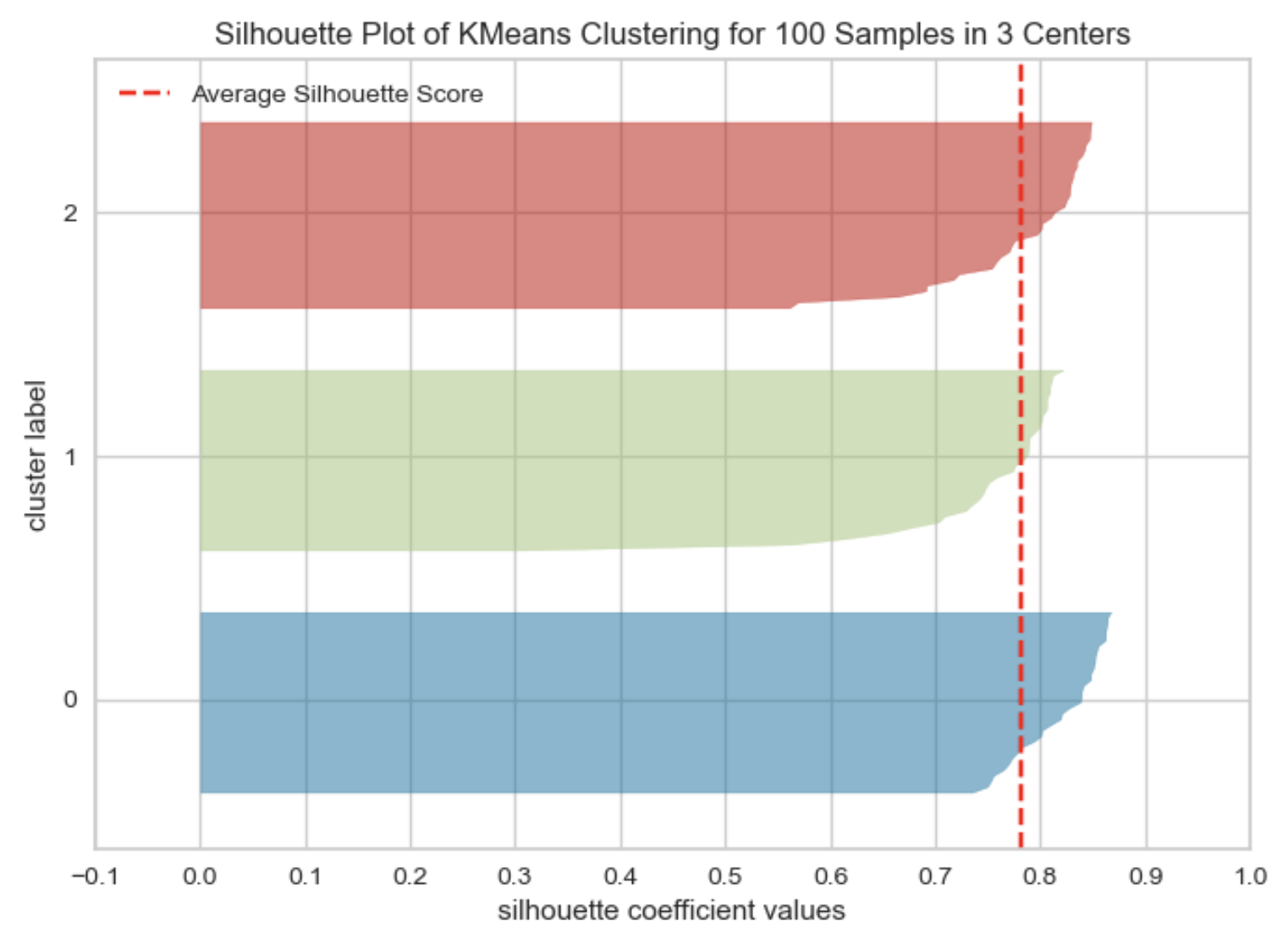
K-means Clustering
- Algorithm Steps:
- Select K initial centroids.
- Assign each data point to the nearest centroid.
- Recalculate centroids based on assigned points.
- Repeat until centroids stabilize or reach a maximum number of iterations.
K-Means example
![]()
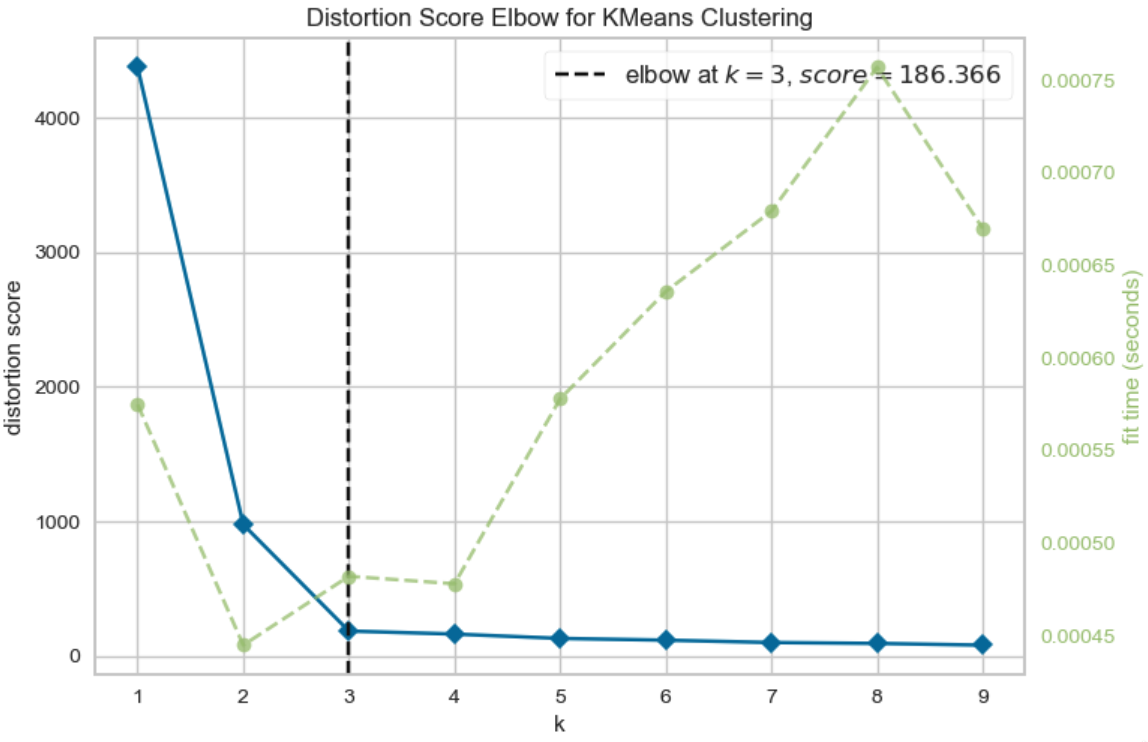
K-Means pros and cons
- Advantages:
- Simple and efficient for large datasets.
- Works well with spherical clusters.
- Limitations:
- Needs pre-defined K.
- Sensitive to outliers and initial centroid placement.
iClicker Exercise 15.1
Select all of the following statements which are True
- K-Means algorithm always converges to the same solution.
- K in K-Means should always be ≤ # of features.
- In K-Means, it makes sense to have K ≤ # of examples.
- In K-Means, in some iterations some points may be left unassigned.
iClicker Exercise 15.2
Select all of the following statements which are True
- K-Means is sensitive to initialization and the solution may change depending upon the initialization.
- K-means terminates when the number of clusters does not increase between iterations.
- K-means terminates when the centroid locations do not change between iterations.
- K-Means is guaranteed to find the optimal solution.


 Reference: Malcolm Gladwell’s Ted talk
Reference: Malcolm Gladwell’s Ted talk