CPSC 330 Lecture 16: DBSCAN, Hierarchical Clustering
Announcements
- HW5 extension: Was due yesterday
- HW6 is due next week Wednesday.
- Computationally intensive
- You need to install many packages

Shape of clusters
- Good for spherical clusters of more or less equal sizes
![]()
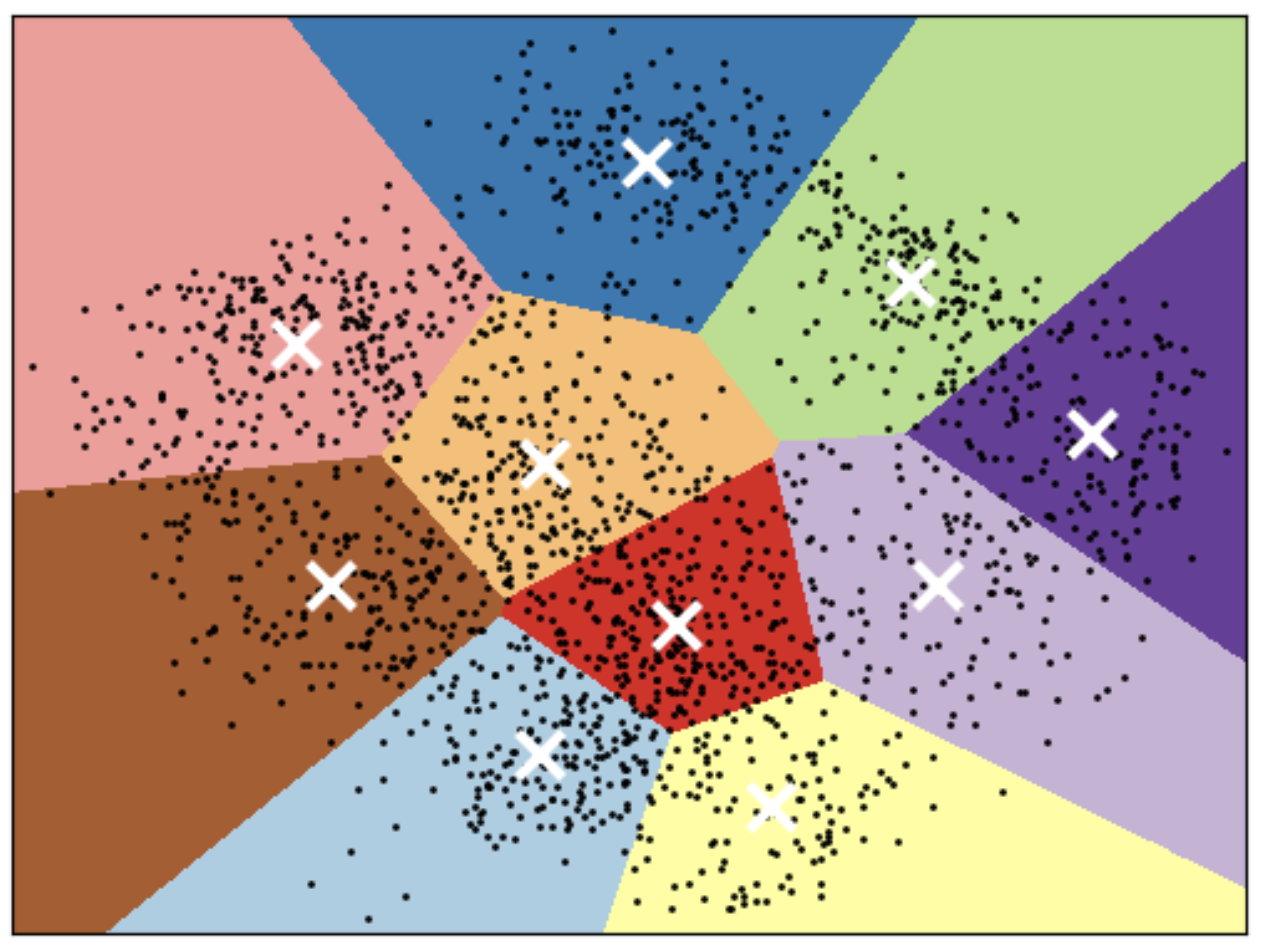
K-Means: failure case 1
- K-Means performs poorly if the clusters have more complex shapes (e.g., two moons data below).

K-Means: failure case 2
- Again, K-Means is unable to capture complex cluster shapes.

K-Means: failure case 3
- It assumes that all directions are equally important for each cluster and fails to identify non-spherical clusters.

DBSCAN
- Density-Based Spatial Clustering of Applications with Noise
- A density-based clustering algorithm

How does it work?
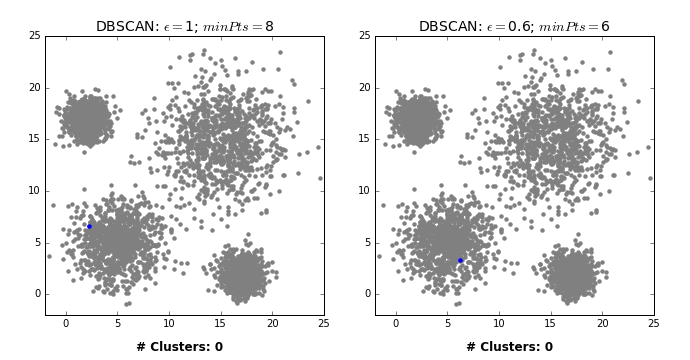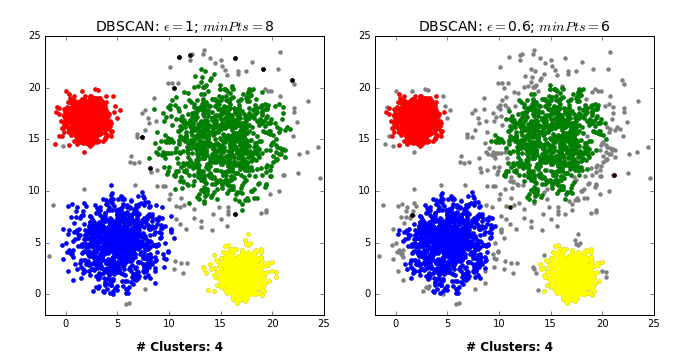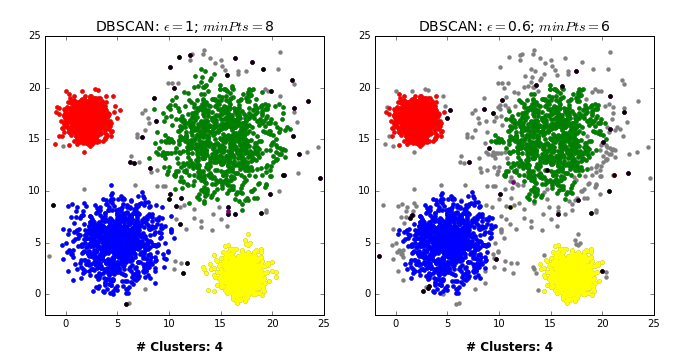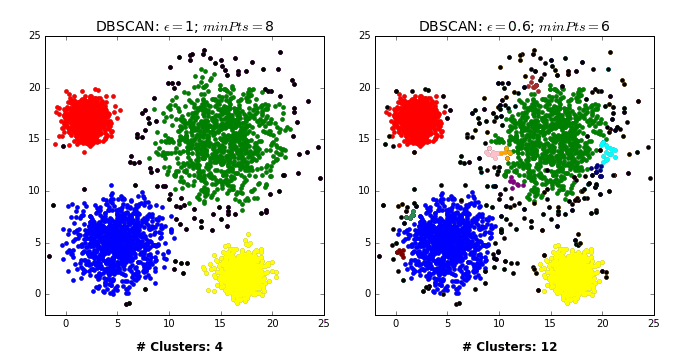
DBSCAN: failure cases
- Let’s consider this dataset with three clusters of varying densities.
- K-Means performs better compared to DBSCAN. But it has the benefit of knowing the value of K in advance.
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
Hierarchical clustering

Flat clusters
- This is good but how can we get cluster labels from a dendrogram?
- We can bring the clustering to a “flat” format use
fcluster

Class demo
![]()