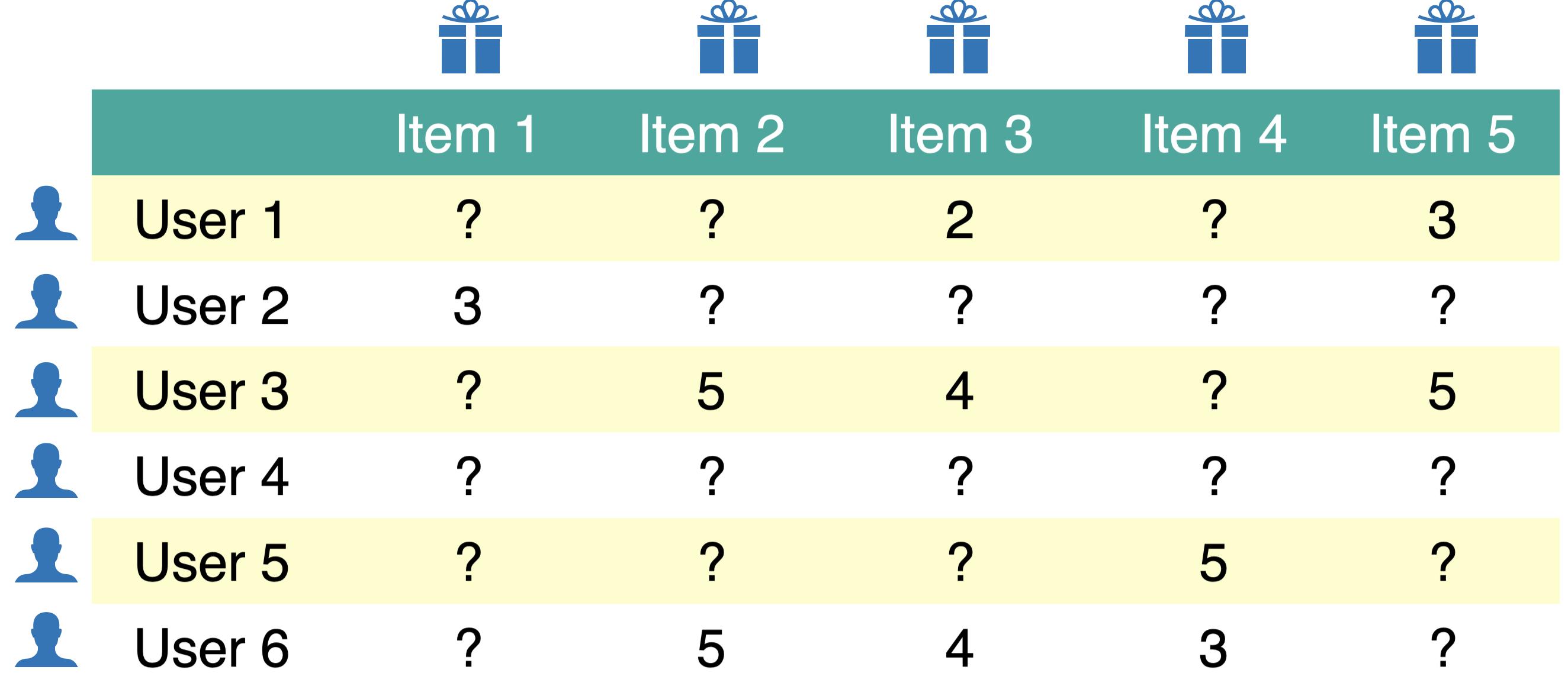
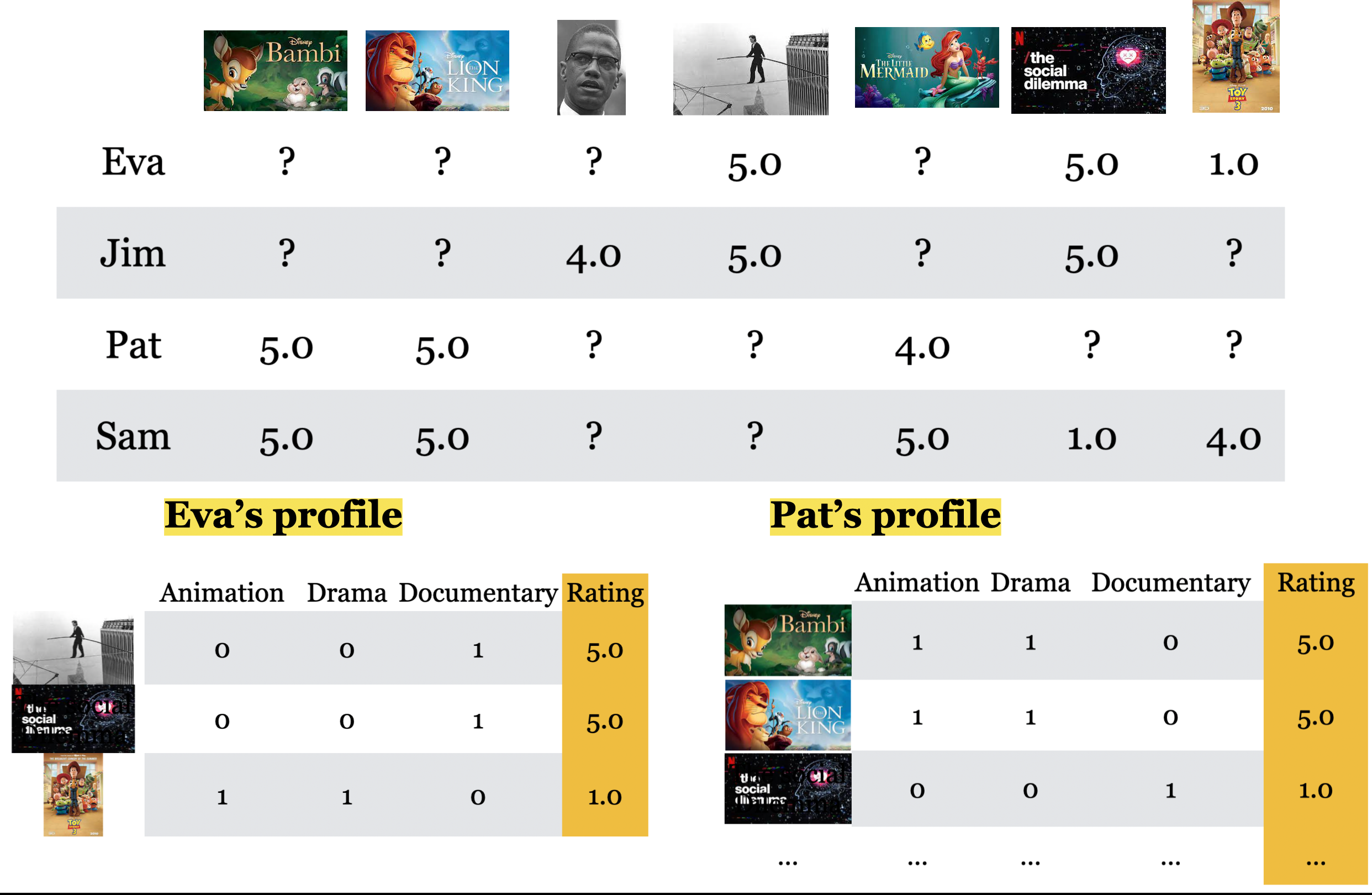
Content-based filtering
iClicker
Select all of the following statements which are True
- In content-based filtering we leverage available item features in addition to similarity between users.
- In content-based filtering you represent each user in terms of known features of items.
- In the set up of content-based filtering we discussed, if you have a new movie, you would have problems predicting ratings for that movie.
- In content-based filtering if a user has a number of ratings in the training utility matrix but does not have any ratings in the validation utility matrix then we won’t be able to calculate RMSE for the validation utility matrix.